人工智能與網絡保安
近年,人工智能於企業的應用經歷了快速增長。根據國際數據資訊有限公司(International Data Corporation)預測,世界各地的企業計劃在 2022年投放於人工智能方案(例如硬件、軟件、服務等)的支出將會增加19.6%,達4,328億美元,到2023年更會超過5,000億美元[1]。隨著人工智能的應用變得多樣化,大家必須更加關注其相關的安全風險。否則,最終可能弊多於利。

什麼是人工智能?
人工智能,普遍指通過電腦程式呈現人類智能的技術,這些人類智能包括學習、解難和辨識規律等。隨著人工智能所紮根之技術蓬勃發展,如電腦性能、數據體積與有關學科研究(如機械人學和統計學)。
人工智能的應用日益廣泛,從廣為人知的電腦視覺(如圖像識別和人面辨識),語言處理(如翻譯和語音辨識),逐漸拓展至模仿人類認知,如癌症判斷,甚至法律案件分析,作詩繪畫等。在網絡安全中,人工智能亦可用以辨識惡意程式[2]。
人工智能與機器學習
機器學習一詞經常與人工智能湊在一起,但其實兩者不是百分百等同。機器學習可以說是人工智能的分支,具體是指透過數學和統計學學習數據,開發出一個模型來對未來結果作預測和解決難題,如同人類從過往經歷汲取經驗以獲得知識推演未來一樣。
機器學習與傳統編程
人們可以將編程視為處理輸入和產生輸出的“規則”的設計。機器學習所做的是通過從足夠程度的已知輸入和輸出中獲得洞察力,然後變成“規則”來處理未來的輸入並執行命令以自動產生足夠準確的輸出 [3]。
監督學習
機器學習的方法眾多,其中最常見的是監督學習(Supervised Learning)[4]。
基本原理
監督學習下,收集數據集以訓練一個數學模型 (Model),數據集內的數據包含一個或多個的輸入(或稱特徵 Feature) 及輸出(或稱標籤 Label),將這些特徵和標籤放入一些算式,計算出演算法用來預測輸出。
圖一:機器學習的基本原理,蘋果和士多啤梨影像及其特徵被稱為特徵,所表達的物件則是標籤
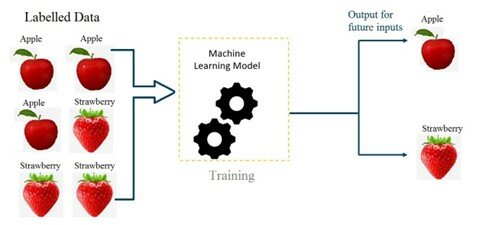
圖片來源: https://ai.plainenglish.io/introduction-to-machine-learning-2316e048ade3 [5]
改善模型 - 梯度下降法 (Gradient Descent)
起初,除了隨機猜測外,模型不知道如何預測輸出。該模型通過梯度下降的優化技術逐漸“學習”作出更準確的預測。
透過比較預測輸出以及實際輸出之相差,便能得出一個損失函數 (Loss Function) 以評估模型的表現,損失函數愈小代表兩者的輸出結果接近,再透過調整算式的參數來將損失函數減至最小[6]。
人工智能系統之網絡保安風險
對比傳統系統,人工智能系統具有更深層次、更廣泛的潛在網絡保安風險。
首先,如上文所述,人工智能建基於大量數據和計算,若這些數據中包含敏感資料,一旦洩漏便會導致敏感資料被披露[7]。
其次,收集的數據之收集可能來自多個來源,當中亦有交叉洩露的危險。例如訓練一疾病偵測模型,需向多間醫院收集病人的生理特徵作分析,收集數據時需確保醫院間不能互相存取病人資料。
第三,若受惡意攻擊,影響範圍更廣。如多個服務使用同一模型,當模型受到攻擊篡改,則所有使用該模型的服務皆會受到波及。
無論你是人工智能的使用者與否,人工智能所帶來的網絡保安風險都可能影響你。在此以「保安漏洞」和「濫用」兩方面,討論人工智能對不同人士帶來的影響。
保安漏洞
成員推斷攻擊 (Membership Inference Attack)
是對機器學習模型(下稱目標模型)的輸出進行逆向工程 (Reverse Engineering),從而推斷出用作訓練目標模型的數據[8][9]。此攻擊的原理是因目標模型對已見和未見的輸入有不同的表現[10],如置信度 (Confidence Level),故只需觀察模型的輸出,便有可能推斷某一輸入數據是否在訓練數據集內。
方法是按照目標模型的結構以及與訓練數據集相似的數據,訓練一些影子模型 (Shadow Model),使得此模型與目標模型的行為表現相似。最後,以影子模型和習成學習 (Ensemble Learning) 建構一攻擊模型,用以判斷某一輸入是否在訓練數據集內。
圖二:以影子模型和習成學習建構一攻擊模型
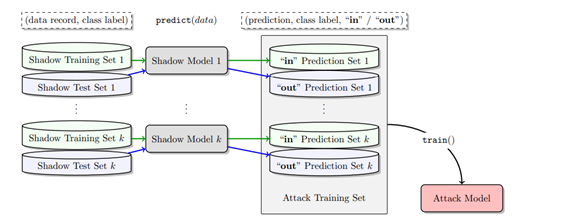
圖片來源: https://arxiv.org/pdf/1610.05820.pdf [10]
研究指出,於此方法下,即使攻擊者並不清楚目標模型的具體結構,只要知道輸入輸出,仍有機會能以相似模式訓練影子模型。現今機器學習即服務 (Machine Learning as a Service) 盛行,攻擊者可以使用訓練目標模型之服務平台訓練影子模型。再者,若攻擊者沒有相似的數據,亦可透過向目標模型查詢,觀察輸出置信度來篩選與目標模型訓練數據集相似的數據。
此類型攻擊較容易針對表格類數據 (Tabular Data) ,如銀行和醫療資訊等。美國康奈爾大學一份研究報告指出,使用成員推斷攻擊,能從德州的醫院的病人紀錄中,推斷出百分之60的數據。這些數據包括診斷,手術類型,受傷原因等敏感資料。
對抗性干擾 (Adversarial Perturbation)
對抗性干擾是指刻意提供錯誤數據以干擾機械學習模型之判斷。其基本原理為透過對數據作微小更動,增加目標模型之誤差。具體手法有二:
閃避攻擊(一次性衝擊)
它通過引入無意義的輸入(即噪聲),引導模型對某個目標數據類別進行錯誤分類,以獲得攻擊者的期望標籤[11]。 這種輸入篡改可能不明顯,但在欺騙學習模型方面仍然非常有效。
Google的一篇會議論文展示了以下概念和潛在結果:熊貓添加了合適的噪聲,模型將其錯誤分類為長臂猿。
圖三:閃避攻擊示範

圖片來源: https://arxiv.org/pdf/1412.6572.pdf [12]
中毒襲擊(重大影響)
它引入了誤導性的訓練數據,使模型誤分類。攻擊者在數據學習階段破壞了 AI 模型,並將操縱的數據注入其中 [13],目的是破壞模型並在未來產生攻擊者所需的輸出。它具有嚴重的影響,因為如果不被發現,它會嚴重影響模型。攻擊若不被發現,能持續影響目標模型之判斷。
例如在2017年,Gmail的垃圾郵件過濾器遭受攻擊,攻擊者透過集體報告垃圾郵件為非垃圾,使錯誤數據成為過濾器的訓練數據,從而令其不能過濾掉某類垃圾郵件,最後攻擊者便能發放釣魚電郵而不被偵測[14]。
另外在2016年,微軟 (Microsoft) 開放了聊天機械人Tay.ai,它能從用戶與自己的對話中學習,提升機械人能力。一些網民向Tay.ai 發出大量帶有仇恨和歧視的言論,使它向用戶說出這些言論,此項計劃最終在開放使用後16小時便下架[15]。
Bosch AI 的研究指出,透過對一幅有行人的街景圖加入噪音,即可令圖像分辨模型無法偵測行人(圖四)[16]。如果以這種方式攻擊自動駕駛系統,汽車可能會撞向行人並造成嚴重的傷亡。
圖四:模型對原圖之分析(右上) vs添加了噪音後對圖像之分析(右下)

圖片來源: https://www.bosch-ai.com/research/research-applications/universal-adversarial-perturbations/[16]
此攻擊的另一個惡意應用是利用使用客戶反饋作為輸入的機器學習模型中使用的重新培訓機制。例如,一些在線購物推薦算法可能會將客戶的瀏覽行為作為數據進行再訓練。攻擊者可以影響模型以獲得所需的結果。
人工智能的濫用
深度偽造 (深偽,Deepfake)
深度偽造是深度學習 (Deep Learning) 和偽造的混成詞。泛指以人工智能製作偽造訊息,如影像和聲音。常見於影片,影片中的人臉將被換成另一人面。這種技術亦可被用於偽造人聲,只需輸入字句便能假借受害者之聲線讀出,意味著製作深偽影片毋須有配音員。
深偽技術現在更發展到可將語音和影片中人的嘴唇同步[17]。深偽的主要學習演算法有自編碼器 (Autoencoder) 和生成對抗網絡 (Generative Adversarial Network)。
近年來,進行深度偽造的技術門檻逐漸降低,在Github上有多個開源軟件能用作製作深偽影片。深偽技術雖然有其娛樂價值,如製作電影和網絡迷因 (meme),但亦可被用以勒索,製作色情影片,散播謠言,甚至繞過生物特徵認證,盜取他人身份 。
例如在2022俄羅斯烏克蘭戰爭中,兩國總統普京及澤連斯基的肖像亦被用作製造深偽影片以傳播謠言。
影片一:深偽影片假扮烏克蘭總統澤連斯基
影片來源:https://www.youtube.com/watch?v=X17yrEV5sl4 [18]
影片二:深偽影片假扮俄羅斯總統普京
Президент РФ обьявил о капитуляции россии. Русский солдат, бросай оружие и иди домой, пока жив! pic.twitter.com/5wWC3UlpYr
— Serhii Sternenko (@sternenko) March 16, 2022
近日美國聯邦調查局政府報導,有騙徒透過深偽技術冒充求職者,到科技公司面試遙距工作的崗位,從而存取公司的客戶和財政數據[20]。
2020年 Microsoft 與 Facebook (現Meta)曾舉辦換臉偵測大賽,第一名僅有65.18%準確度,可見暫時並未有科技能完全識別深偽[21]。
要注意的是,現時技術仍需要大量肖像的相片作訓練數據,才能製作難以辨認的深度偽造影片,故這些影片的偽造對象通常都是公眾人物,因在互聯網上可輕易搜尋到可供機器學習的公眾人物材料。
保安建議
要處理這些風險,可從技術的方向入手,如驗證數據,使用防偽工具,避免學習模型擬合過度等。一些現有的網絡保安措施亦有助避免這些問題,如數據的保密在人工智能的發展上必不可少。即使不是科技達人,用戶仍然有一些措施可以保護自己,如加深對這些科技的認知和不盲目相信網上資訊。
選擇適合的模型,以避免成員推斷攻擊
成員推斷攻擊憑著模型對已見和未見的數據有不同表現,推斷出某一數據是否屬於訓練數據集。若一訓練模型的分析過份貼近已見數據,即使能準確地標籤已見過的數據,仍然無法良好地標籤未曾見過的數據,此現象在統計學中稱為擬合過度 (Overfitting) ,擬合過度的模型對於處理已見和未見數據的準確度落差甚大, 故容易受成員推斷攻擊[22]。
訓練模型參數過多,數據噪音過多或未經處理和數據量不足夠等都能導致擬合過度。若要避免擬合過度,便要確保選擇適合的模型,切忌只是以標籤訓練數據的準確度衡量模型表現。一些準確度的驗證方法,如k折交叉驗證,能使模型準確度更貼近其表現,避免誤選擬合過度的模型。訓練模型時,亦要確保數據充足以及經過整理,以及定期檢查誤差值有否隨訓練時間而上升,及早暫停訓練。
更新學習模型前驗證數據,以避免對抗性干擾
現時許多使用人工智能的服務,亦會以用戶反饋作為訓練數據調整模型,意味著用戶的行動能改變模型的行為,使得攻擊者有機可乘。故在更新學習模型時要驗證這些新數據的真偽,亦可限制每位用家的反饋輸入數量,以避免少部分用家決定學習模型的改變去向[23]。
改善特權存取管理(PAM)制度
能限制員工和用戶對訓練數據的存取權,從而避免訓練數據遭到修改。
使用防偽工具避免深度偽造
現時有許多防偽工具能幫助我們辨認出深偽影片。例如在原照片中加入電子水印,若影片遭到深度偽造, 電子水印將會改變,因此可以更容易識別合成影片。暫時,許多Deepfake影片仍未完美,憑肉眼觀察亦可能發現是深偽,Kaspersky提出幾個Deepfake 影片的特徵[24]:
- 移動不流暢
- 從一幀到下一幀的光影不流暢
- 膚色不調和
- 眨眼規律奇怪或沒有眨眼
- 嘴唇與話語不脗合
你可以回到上面的深偽影片,看看你能否用肉眼識別。
(註:這些特徵只是對暫時質素較差的深偽影片有用,若未來深偽影片的像真度提升,未必可以用肉眼觀察到)
加強對深偽的認知
除了要有相應的科技識別和對治深度偽造,培養對深偽影片的警惕和意識亦必不可少。例如了解深偽影片能帶來的危害和損失,以及提升媒體素養:觀看新聞時要取用可信的媒體,多作比較不同的消息來源、時常驗證不盲目信任。
總結
隨著人工智能的能力提升,人工智能亦被用作武器,今時今日,無論你是人工智能的使用者與否,都有機會成為這些攻擊的受害者。了解人工智能衍生的網絡保安風險,便能安心享受人工智能帶來的便利。
參考資料
[1] https://www.idc.com/getdoc.jsp?containerId=prUS48881422
[2] https://techbeacon.com/security/how-ai-will-help-fight-against-malware
[3] https://machinelearningmastery.com/basic-concepts-in-machine-learning/
[4] https://www.youtube.com/watch?v=Ye018rCVvOo
[5] https://ai.plainenglish.io/introduction-to-machine-learning-2316e048ade3
[6] https://machinelearningmastery.com/gradient-descent-for-machine-learning/
[7] https://hubsecurity.com/blog/cyber-security/security-threats-for-ai-and-machine-learning/
[8] https://bdtechtalks.com/2021/04/23/machine-learning-membership-inference-attacks/
[9] https://www.youtube.com/watch?v=rDm1n2gceJY
[10] https://arxiv.org/pdf/1610.05820.pdf
[12] https://arxiv.org/pdf/1412.6572.pdf
[13] https://towardsdatascience.com/poisoning-attacks-on-machine-learning-1ff247c254db
[14] https://elie.net/blog/ai/attacks-against-machine-learning-an-overview/
[16] https://www.bosch-ai.com/research/research-applications/universal-adversarial-perturbations/
[17] https://bhaasha.iiit.ac.in/lipsync/
[18] https://www.youtube.com/watch?v=X17yrEV5sl4
[21] https://pansci.asia/archives/342421
[22] https://elitedatascience.com/overfitting-in-machine-learning
[24] https://www.kaspersky.com/resource-center/threats/protect-yourself-from-deep-fake
相關標籤
分享至